Una clave ajena (FK) es una columna o combinación de columnas que se utiliza para establecer y exigir un vínculo entre los datos de dos tablas. Es posible definir una clave ajena mediante la definición de una restricción FOREIGN KEY cuando se crea la tabla, o mediante un comando ALTER TABLE ADD COLUMN.
Por ejemplo, la tabla “Maestro” de la imagen posee una clave primaria denominada id, mientras que la tabla “Esclavo” posee una relación lógica con “Maestro” a través de la columna fk_maestro. La columna fk_maestro entonces es designada como la clave ajena de Esclavo hacia Maestro.
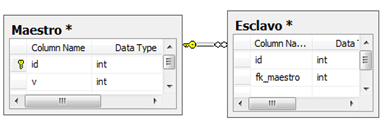
La restriccion FOREIGN KEY en nuestro caso, establece y exige dicho vínculo de datos forzando a que no sea posible introducir un valor en fk_maestro, que no exista en la columna id de la tabla Maestro. Gracias a ello, el motor de base de datos puede generar planes de ejecución óptimos.
Una cosa que tenemos que conocer es que una restricción FOREIGN KEY soporta que se introduzcan valores NULL pero que cuando estamos ante una clave FOREIGN KEY compuesta por varias columnas y en una de ellas se introduce un NULL, se omite la comprobación de los valores que componen la restricción FOREIGN KEY. Por tanto, es buena práctica especificar NOT NULL en todas las columnas que participan en la misma.
Cuando una clave ajena se encuentra marcada como “confiable”, se garantiza que todas las filas de la tabla cumplen la restricción de clave ajena y se ayuda al planificador a generar un plan de ejecución mas efectivo. Vamos a verlo con un ejemplo que utiliza las dos tablas de la imagen anterior:
SET NOCOUNT ON
DROP TABLE dbo.Esclavo;
DROP TABLE dbo.Maestro;
GO
-- creacion de tablas con tipica relacion maestro-esclavo
CREATE TABLE dbo.Maestro(
id INT IDENTITY (1,1) primary key,
v int
)
create table dbo.Esclavo(
id int identity(1,1),
fk_maestro int --foreign key references Maestro(id)
)
Go
-- Añado la relación, por defecto es confiable y activada
--
alter table dbo.Esclavo add constraint fk_esclavo_maestro foreign key (fk_maestro) references Maestro(id)
GO
-- inserto 1000 filas
--
DECLARE @i INT
SET @i=0
WHILE @i < 1000
BEGIN
INSERT dbo.Maestro (v) VALUES (@i)
SET @i=@i+1
END
GO
-- inserto en esclavo datos válidos apuntando al maestro
insert into dbo.Esclavo (fk_maestro)
select id from dbo.Maestro
GO
-- esto obviamente da error por la clave ajena
insert into dbo.Esclavo (fk_maestro) values (20000)
-- deshabilito el check, porque queremos realizar un bulk insert , por ejemplo
ALTER TABLE dbo.Esclavo WITH noCHECK noCHECK CONSTRAINT fk_esclavo_maestro
-- vemos el estado no confiable y que ademas no se comprueba la restriccion
--
SELECT name as [Nombre FK],object_name(parent_object_id) as Tabla, schema_name(schema_id) as [Schema Name],is_not_trusted,is_disabled
FROM sys.foreign_keys
-- ahora me deja hacer el insert, pese a ser inválido el valor en el esclavo
--
insert into dbo.Esclavo (fk_maestro) values (20000)
-- ahora vuelvo a habilitar el check, pero marcando que no se comprueben los datos anteriores, sino para los nuevos
--
ALTER TABLE dbo.Esclavo WITH noCHECK CHECK CONSTRAINT fk_esclavo_maestro
-- ahora esta como not trusted , pero a partir de ya, se vuelven a comprobar las fk
--
SELECT name as [Nombre FK],object_name(parent_object_id) as Tabla, schema_name(schema_id) as [Schema Name],is_not_trusted,is_disabled
FROM sys.foreign_keys
-- ahora ya no me deja insertar basura
insert into dbo.Esclavo (fk_maestro) values (20001)
SET STATISTICS IO ON
-- con disabled y not_trusted
-- Table 'Maestro'. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
-- Table 'Esclavo'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
--
select fk_maestro from dbo.Esclavo e inner join dbo.Maestro m on m.id = e.fk_maestro and fk_maestro >1001
-- SI AHORA HABILITAMOS Y LO VOLVEMOS A PONER COMO TRUSTED, YA NO SE CONSULTA A
-- MAESTRO, con la consiguiente mejora de rendimiento
-- primero hemos de borrar la basura
delete from dbo.Esclavo where fk_maestro > 1000
ALTER TABLE dbo.Esclavo WITH CHECK CHECK CONSTRAINT fk_esclavo_maestro
-- Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
-- Table 'Esclavo'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
--
select fk_maestro from dbo.Esclavo e inner join dbo.Maestro m on m.id = e.fk_maestro and fk_maestro >1001
Vemos en el ejemplo como si tenemos la clave FOREIGN KEY como confiable, no es necesario que SQL Server consulte contra la tabla Maestro para resolver la consulta. Si la clave está como no confiable evidentemente se incurre en una penalización de rendimiento que en todo caso y ahora que sabemos que existe, querremos evitar siempre.
Las restricciones marcadas como “no-confiables” lo están porque o bien se han creado con la marca “WITH NOCHECK” , o bien se han deshabilitado en algún momento manualmente por un proceso de carga masivo o de replica.
No vamos a poder marcar la clave ajena como “confiable” hasta que no habilitemos la clave ajena con comprobación de datos previos, y esto se hace de la siguiente manera:
alter table Tabla with check CHECK CONSTRAINT NOMBRE_FK
Nota: Al lanzar esta sentencia, se comprobaran las restricciones de clave ajena para los datos ya insertados con lo que si existe algún dato inválido no se va a activar, teniendo nosotros que solucionar la inconsistencia para poder continuar.

